


There is a misconception that only oracles can handle on-chain data. It is the same way of thinking we had before blockchain, that only a bank can store our money. In reality, oracle networks have no divine right or special ability to upload the data we need to chain—anyone can commit data to chain.
Since the rise of Chainlink, there have been dozens of attempts to take down the giant. But all others have fallen into the same custodial, third party approach, so the king still stands.
Ontropy solves the oracle problem and eliminates its billions of dollars in exploits by doing to data what blockchain did to money: letting the end users validate it.
Source: Ontropy
Abstract
Ontropy is eliminating third-party oracles through user-validated data.
The problem is that oracles, like ChainLink, are centralized. This leads to 12 second latency, a hundred million dollars in gas fees, and billions of dollars in exploits.
So, how do we solve it? By eliminating the third party oracle and middleman and allowing the users to directly validate the data themselves. Now there is a misconception that oracles are useful because they put off-chain data on chain. This is untrue. Anyone can put off-chain data on-chain. If we are doing a transaction, I can put that information on chain myself. The problem is that my counterparty will not trust me, and vice versa. This is why we use an oracle, it is a source that puts off-chain data on-chain, and is trusted. But when you have trust, you risk that trust being broken. And that’s why we lost $3 billion in oracle exploits last year.
So, I said that we can’t put the data on-chain ourselves because we cannot trust each other, as we do not have aligned incentives. But what if we could? What if we could trust each other and did have aligned incentives? This is what Ontropy does. We use two mechanisms, one game theoretical to eliminate third parties and one cryptographical to remove counterparty risk. Together, they make up Proof of Result. Essentially, just me and you verify the data, exchange some proofs of our agreement, and put it on chain ourselves. What we’ve done is kill third-party oracles and the cost, latency, and exploitations that come with them.
If we’re doing a swap and agreeing to the price ourselves, that’s great. We’ve eliminated oracles for our own transaction. What we’ve also done is implicitly validate the price we agreed to up to the value of the transaction. If we traded 5 ETH at a price of $1,600, for example, we can say that the data has $8,000 of volume. If others implement this process, to reduce latency and prevent exploitations for their own purposes, then we have effectively created a constant stream of user-validated data. We have crowdsourced price feeds and natively brought assets prices on chain. The chain then becomes the reference point for the data itself. No more oracles.
The Oracle Problem
It is not a hot take to say that oracles are a compromise. And yet, oracle networks like Chainlink are carrying all of DeFi on their back—the constant flow of price feeds on-chain has been essential at informing liquidators, swappers, and stakers. But in actuality, this flow has been latent, expensive to maintain, and riddled with exploits.
While the movement of crypto is validated by hundreds with approval of thousands, blockchain data used by millions is checked by as little as one. This is because information is inherently external, so we must rely on specialized entities to verify and commit the price feeds.
This involves some level of trust, not only for the oracles, but for the centralized APIs on which they rely. Of course, this is the result of trust in centralized third parties:

Source: Ontropy, The New York Times, Binance, CoinDesk, CoinTelegraph, Certik
If we are to view the blockchain as a perfect paradigm for the movement and storage of capital: non-custodial, permissionless, immutable, and with decentralized consensus; then we can begin to deconstruct the transgressions of oracles and what a perfect system would look like.
The problematic characteristics of oracles:
Very Custodial
Data is carried into the chain by a few institutions and validated only by themselves.
Information should be treated as a public good, as it is non-rivalrous and non-excludable. But, the oracle business model is not fit for data, failing not only free-flowing information, but their revenue stream.
The oracle is a centralized aggregator, but latency concerns prevent this bundling from being externally verified.
The origin of the data is from centralized sources, leading to two third-party points of failure.
Not Permissionless
It is difficult to become an oracle node, there is a top-down imposed reliability metric that is not fully determined by the users.
Even if one is able to become a node, most volume goes to large institutions.
Slow relationships and redundant infrastructure must be established before launching on new chains.
Price feeds can be unilaterally shut down or altered at any time.
Immutable
Oracle networks are immutable, as they reach finality on chain. But this leaves a 2-12 second block organizing window for searchers to extract MEV and for rapid price fluctuations. In short, immutability is too latent and intra-block data is unsecure.
Centralized Consensus
Oracles suffer from the cost-size dilemma, whereby increasing security exacerbates cost. This is why all networks, like Chainlink, have only 30 or so nodes on most major chains.
The associated cost for just this quantity of nodes is between 10 and 20 million dollars per year.
This cost is primarily made up of recurring gas fees on the host chain, which if removed, would noticeably lower transaction costs for everyone else.
Only a fraction of the total nodes are active at one time, meaning data that secures billions of dollars in assets is controlled by a few third parties which themselves rely on centralized endpoints.
This is the oracle problem.
The oracle is custodial and reliant on third party trust
The network is gated with mainly institutions participating
Data reaches finality too slowly
Sustaining data feeds is very cost-intensive
Consensus in centralized, which has led to billions in exploits
At their worst, oracles give us 12 seconds of latency, 100 million dollars in annual gas, and over $3 billion in exploits over just the last year alone.
Now these shortcomings are well established, this is why the likes of SupraOracles, Pyth, RedStone, and API3 have all attempted to make “better” oracles. Some try to increase validator count, or make “first-party” oracles. None have achieved significant traction.
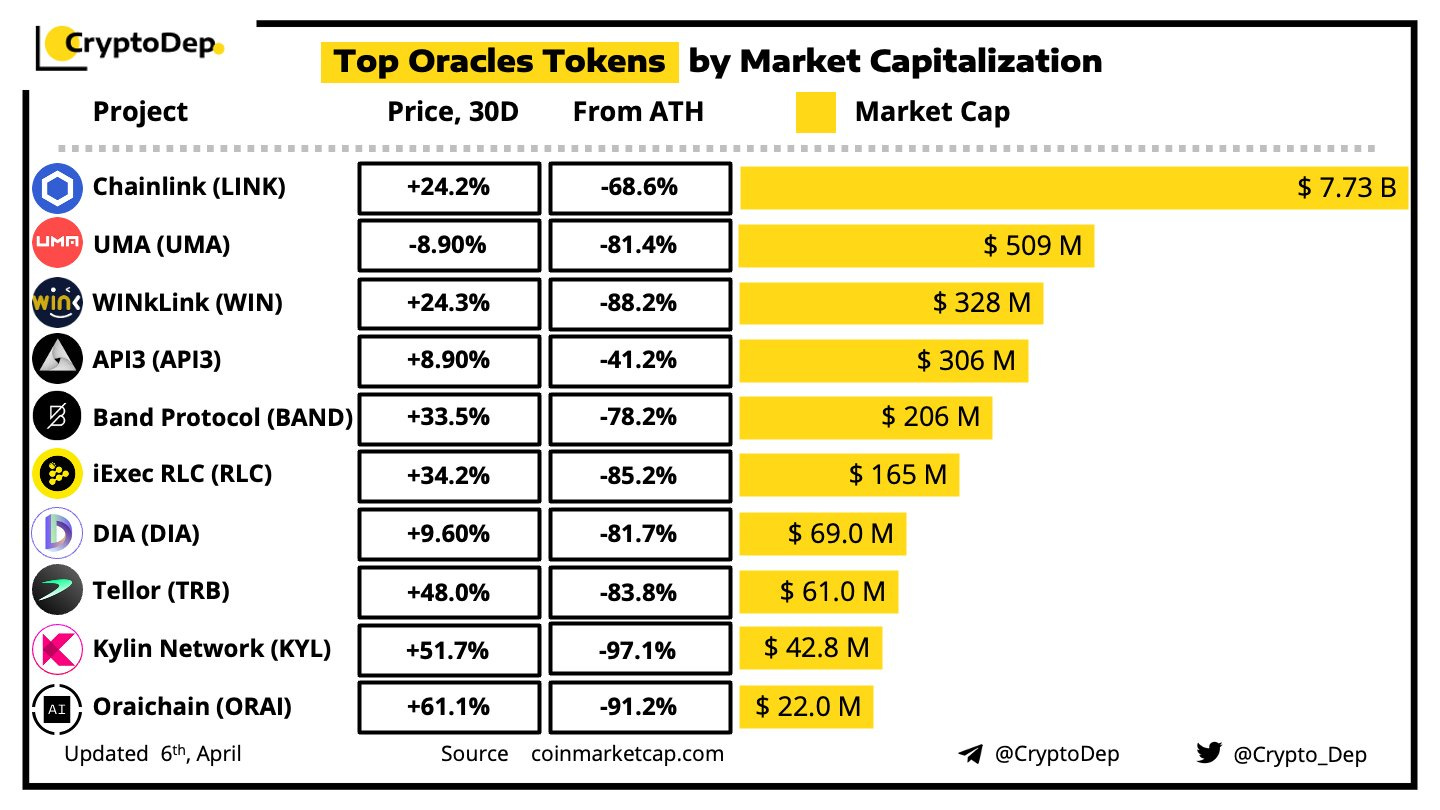

Logarithmic and Linear Chainlink market dominance charts, Source: Crypto_Dep
Everyone has tried to make a “better” oracle network…you can’t make a better oracle. Scaling will always be expensive and first party providers merely defer trust. The solution to the oracle problem is not Oracle 2.0, 3.0, or 4.0, it’s a reimagined data consensus mechanism that leverages all of the users of the blockchain.
User-Validated Data
Users cannot validate their own data because each party is incentivized to raise or lower the price for their own advantage. For example, a liquidator might claim an asset is unfairly low while a call option trader could say it is higher than it actually is.
However, by pairing opposing parties together, a trustless equilibrium is reached where the outcome represents the interests of everyone involved. This is the purpose of Ontropy, to align incentives through cryptography and game theory so that users can exchange and agree to data. Let’s walk through a simple example where two users want to swap ETH and MATIC.
Both users will attain the price of both ETH and MATIC from endpoints like CoinDesk, Binance, CoinMarketCap, and Coinbase
Users will create a DKG field and apply ZK proofs to the ETH and MATIC values they attained
The users will exchange these proofs p2p and test if both of their prices for each asset are within a set tolerance, say 0.5%
Both users will then send their assets to a holding contract with the additional asset price data fields
The holding contract will evaluate if the opposing prices match
and distribute funds immediately if so
If not, a dispute period will open where either user can commit their counterparty’s proof. Then funds will be distributed
Steps 2 and 3 deserve a bit more detail:
The use of zero knowledge proofs allows a party to establish the validity of some statement to another party without disclosing any information about it, apart from the fact that the statement is true.
In the discussed scenario, we can utilize a specialized form of ZKP referred to as a range proof. A range proof enables the prover to confirm that a confidential value is situated within a specified range without disclosing any information about x itself. To accomplish this, the proving party and verifier employ a commitment scheme and engage in the interactive protocols.
Commitment: The prover employs a commitment scheme to conceal the secret value x. This scheme allows the prover to "lock" the secret value in a manner that keeps it hidden while preventing the prover from altering the value later. The commitment is subsequently shared with the verifier.
Range Proof Protocol: The prover and verifier participate in an interactive protocol during which the prover demonstrates that the committed value falls within the desired range, without revealing the value itself.
Verification: The verifier examines the proof provided by the prover to ensure its accuracy. If the proof is deemed valid, the verifier can be confident that the secret value lies within the specified range.
Privacy is helpful in exchanging price information to prevent renegotiation attempts to the end of the ranges.
To learn more, check out our Proof of Result and Off-Chain Consensus articles.
Proof of Result works for a few reasons. The first is because the information is embedded within a transaction that’s already occurring, this reduces cost. It also helps authenticate the data as the asset price cannot be separated from the asset itself. This, along with the incentives for buyers and sellers to find a common price, guarantee every party has agreed and signed the data.
The second is because finality is achieved off-chain. The DKG, ZK, and HE processes would likely cost more to authenticate then the total amount being sent, if performed on chain. By the time the users reached consensus, the price would also be hilariously outdated. The holding contract’s ability to reach instant finality has all the cost benefits of an optimistic rollup with the power of a ZK rollup, but without the proofs or cost.

Source: Ontropy
The final reason Proof of Result works as an off-chain data consensus mechanism is that the entire process is trustless and cheating is unprofitable and impossible. The use of a proof of participation ensures every transacting user receives every relevant piece of data, it’s perfectly fault-tolerant. Exchanged proofs are agreed and signed by every user, to every user. So when information goes on chain, every other user can verify it against the proof they received, and dispute if necessary. Because of this, disputes are unlikely to ever occur as cheating is always unprofitable.
User-Validated Data is a significant improvement over oracles in relation to speed, cost, and security.
Proof of Result occurs off-chain, meaning data can be agreed to with finality achieved at millisecond time. This postpones the need to instantly commit to the blockchain. Meaning, several transactions can occur off-chain, and they can be bundled and settle on chain later, perhaps when gas fees are lowest.
Off-Chain Consensus bundles data with transactions that already need to occur, so fewer total transactions will occur. This reduces user cost and improves overall network efficiency.
Most significantly, user-validated data eliminates third party oracles that have resulted in over 3 billion dollars in exploits in the past 14 months.
Crowdsourcing Price Feeds
In Proof of Result, we used the garage-car analogy to explain trustless off-chain consensus. I ended that segment by stating “There is more to consider, like the scenario where the value of the car falls near or below the loan amount during the repayment period. We’ll explore this in depth in a future post, subscribe to stay updated!” This is that future post.
Proof of Result is fault-tolerant, requiring agreement from every participating user to proceed. This eliminates both third-party and counterparty risk. It does not, however, account for scenarios when it is not in the best interest for a user to participate. For these scenarios, like liquidations, Proof of Result must adapt.
Remember back that one of the core features of PoR is the creation of an additional data field within the asset transaction. The purpose of this is so that our hypothetical MATIC and ETH swappers can compare prices and trade. However, what they have also done is implicitly validate the asset price up to the total value of the assets transacted.
Let us say that the first trader placed 5 ETH in the holding contract with the accompanying, and irrevocable, price. Can we not say that if the opposing trader agrees to the price with a corresponding value of MATIC, that the agreed price has volume of 5 ETH? After all, these users traded for their own purpose, so it would be unprofitable for both of them to transact at a false price. Truth is then derived from opposing interests reaching a conclusion.
Now imagine several of these trades occurring, several times per block. The result is a constant stream of user-validated data. Now one could argue this would be similar to a CEX or DEX. The purpose of Proof of Result is to facilitate the agreement of data, but the result here is indeed an order book.
User-validated data fulfills the promise of an AMM—no oracles as information is natively derived on chain—but will achieve it universally because Proof of Result is not one platform, but an interoperable network that can be applied to every transaction anywhere. Distributed information from CEXs, DEXs, and lending protocols can all be brought to one place, eliminating information asymmetry and intra-asset arbitrage.
Ontropy crowdsources pricefeeds. And with this achieved, even the third-party APIs would no longer be needed.
Price feeds are fundamentally different then every other data type. They do not inherently come from the outside world, like weather or sports data. We reference the price of Ethereum on web2 sources solely because this is where the majority of the volume occurs. In fiat to crypto trades, prices must settle on both networks. They ought to be recorded on the ledger and become a pegged reference point for its own price. Introducing a data field on every transaction will allow the price of ETH, or any other crypto, to live natively on its own chain. No more oracles.
Here is the team doing it.

Source: Ontropy. Ontropy Founding Team, Left to Right:
José, Economics Researcher, Dropout at Yale
Alexander, Ph.D. in Cryptography
Possible Applications in Liquidations, MEV, and Layer Zero
The potential of secure and decentralized off-chain consensus is unbounded. Using price feeds, high-frequency traders can exchange p2p and post on chain afterwards. Reverse repos can recur without being posted publicly but with the assurance that there is sufficient collateral.
While the current system includes only the transacting parties, they could opt in to share their price data with liquidators. Liquidators could pay the transacting parties and Ontropy directly to be involved in the off-chain transaction and receive immutable prices and transaction data intra-block. Even third party oracles could be interested in incorporating this data.
The idea of having access to information up to 12 seconds before everyone else unavoidably brings up MEV. While searchers would be interested in buying these transactions to sell to block proporers, Ontropy could even bring about the elimination of MEV, the creation of a lossless transfer system, and the capture of this efficiency for itself. Because finality is achieved off-chain and the reduction of information disparity brings all traders in line with the same price, it seems possible that all trades could settle at once, every block. This might result in frontrunning and sandwich attacks being substantially weakened.
Decentralized bridges, like LayerZero, can only be exploited if the oracle and relayer collude. The oracles in bridges were exploited to the tune of $1.5 billion in 2022 alone, so this should be viewed as a systemic risk. Because the relayer is often just one central point in the transacting protocol, it is difficult to increase its security. This means the weak point of the entire bridge is the oracle, Chainlink, in LayerZero’s case.
Replacing the oracle with user-validated data transforms the weakest link in a cross-chain bridge from a few nodes to the blockchain itself. This is the Omnichain, an interoperable blockchain network with each bridge as strong as the chains themselves. It begins with Death To Oracles.
Thank you for reading! To stay updated, follow me and Ontropy on Twitter and check out our website. Share your thoughts on Twitter and Discord!
Sources
Nice